-

 エンジニア 2016.03.28AWSのEC2イベントを検知してslackへ通知するBotを作ってみた!
エンジニア 2016.03.28AWSのEC2イベントを検知してslackへ通知するBotを作ってみた! -
エンジニア 2016.03.24AWSのサポートプランを変更する
-
エンジニア 2016.03.23Volunteer Days
-
エンジニア 2016.03.22jqを使ってAWSの情報を取得しよう②
-
エンジニア 2016.03.07jqを使ってAWSの情報を取得しよう①
-
 エンジニア 2016.03.04【JAWS DAYS出張&MAコラボ企画】JAWS DAYS 2016アイディアソンに参加しました!
エンジニア 2016.03.04【JAWS DAYS出張&MAコラボ企画】JAWS DAYS 2016アイディアソンに参加しました! -
エンジニア 2016.03.03stsAssumeRoleについて ー後編ー
-
エンジニア 2016.02.25stsAssumeRoleについて
-
エンジニア 2016.02.24Elastic Beanstalkスケールイン時にlogが消えちゃう問題
-
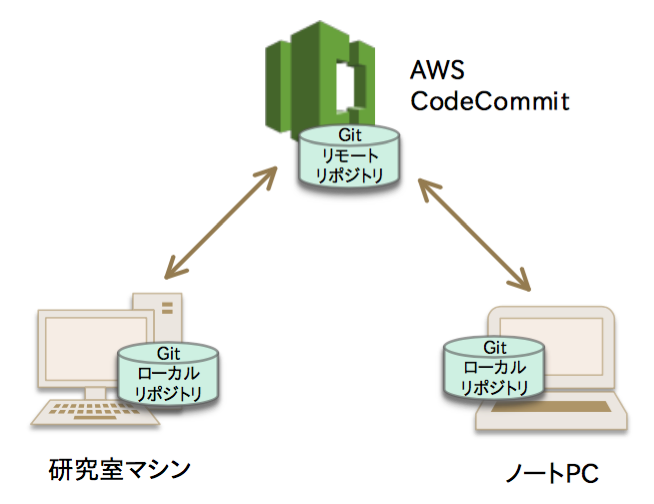 エンジニア 2016.02.24AWS CodeCommitを使ってみた
エンジニア 2016.02.24AWS CodeCommitを使ってみた
CATEGORY
- キーボード部
- Rekognition
- Raspberry Pi
- 開発合宿
- チームビルディング
- リモートワーク
- PHP
- S3
- DynamoDB
- ソフトウェア工学
- Elastic Beanstalk
- IoT部
- Kinesis
- Amazon Machine Learning
- ECサイト運用
- Kinesis Video Streams
- スクラム
- CodeStar
- 暗号通貨
- CI/CD
- GitHub
- AWS WAFv2
- SAPブログリレー
- Django
- ソフトウェアテスト
- 振り返り
- AI
- ChatGPT
- Salesforce
- Java
- IAM
- AWS
- ユニケージ
- 日常
- Python
- Amazon Elasticsearch Service
- 勉強会
- Lambda
- Slack
- 新人研修
- デザイン
- iOS
- イベント
- serverless
- 書籍
- SQS
- CloudWatch
- CodePipeline
- Alexa
- ブロックチェーン
- JavaScript
- 機械学習
- Go
- ECS
- CRMチーム
- Docker
- AWS認定
- Vue.js
LATEST
ARCHIVES